|
If you live in the Bay Area, you may have noticed the smoky haze that covered San Francisco and the surrounding areas earlier this month. Caused by several large wildfires in the Sonoma County, it greatly reduced air quality and visibility, and made me, and many others, reluctant to go outside. You may have also heard in the news about the devastation of Santa Rosa (where the fire destroyed 3,000 homes causing $1.2 billion in damages) along with other communities in the Sonoma County. All the while, the cause of the string of wildfires is still unknown and under investigation. Problem Overview These recent events was my motivation for my third project at Metis, Project McNulty. For this project I aim to create a classification model to predict the cause of a wildfire given its features, and create a tool in the form of a Flask application that could help authorities determine the cause of a fire when reasons are unknown. This application would also be able to determine the highest probable cause of wildfires in a given location to help decision-makers take steps to mitigate the risk. The data I used for this project is a Kaggle dataset and it consists a spatial database of 1.88 million wildfire events that occurred in the United States from 1992 to 2015 and was generated to support the national Fire Program Analysis (FPA) system. Some of the information given for each fire event included the location, the discovery date, the cause, the size, and the containment date. 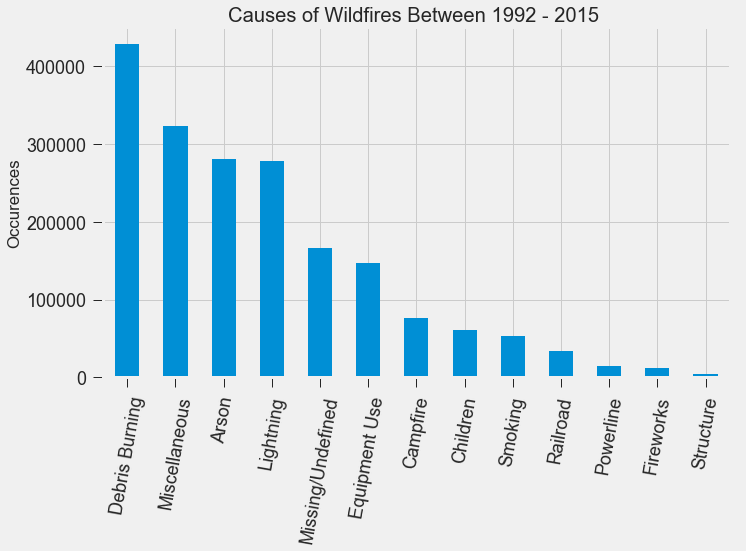 The above graph shows the distribution of wildfire causes in the 24-year period. We can see that over 700,000 cases of wildfires were attributed to two causes: debris burning and "miscellaneous". Debris burning are fires started by people burning trash, crops or other waste materials, and miscellaneous fires are ones that are started by anything that cannot be grouped in any of the other categories, such as fires started by electrical wiring or from other natural sources other than lightning. You can find the description of each category here. I also want to point out the missing/undefined category which I will write about a little later in this blog post. To tackle this dataset, I started with some exploratory data analysis. Exploratory Data Analysis 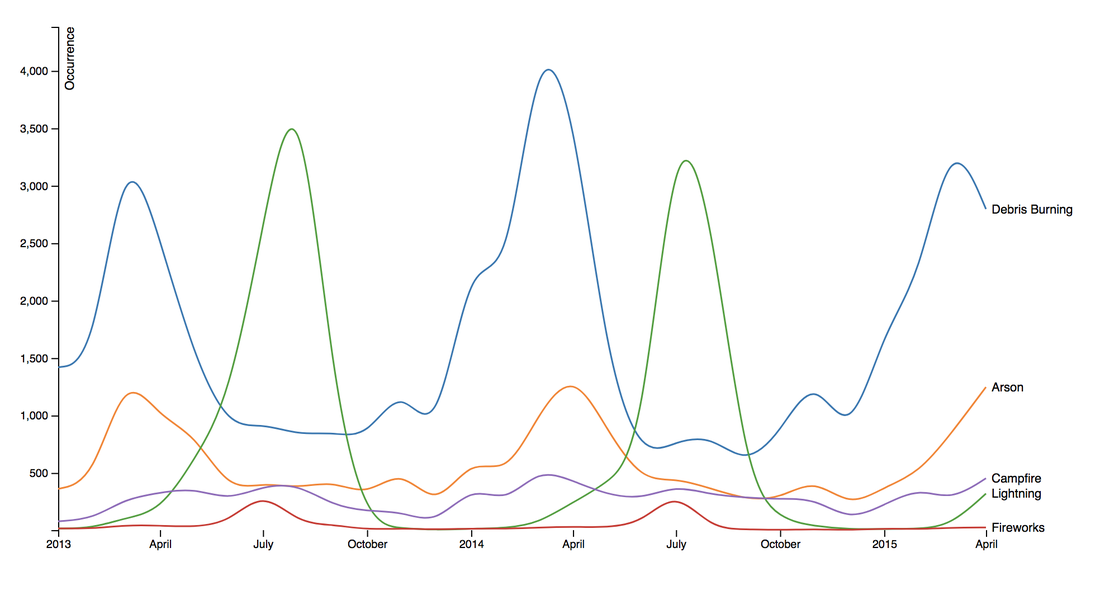 Wildfire Causes Between 2013 - 2015 The plot above highlights five causes of wildfires and plots their total occurrences over time, and by looking at the graph, it's clear that the causes are cyclical. Wildfires caused by debris burning and arson typically happen in late winter or early spring, lightning fires occur in the summer months, and perhaps not surprisingly, wildfires caused by fireworks occur in early July. There also seems to be no apparent pattern for wildfires caused by campfires, which is somewhat surprising. 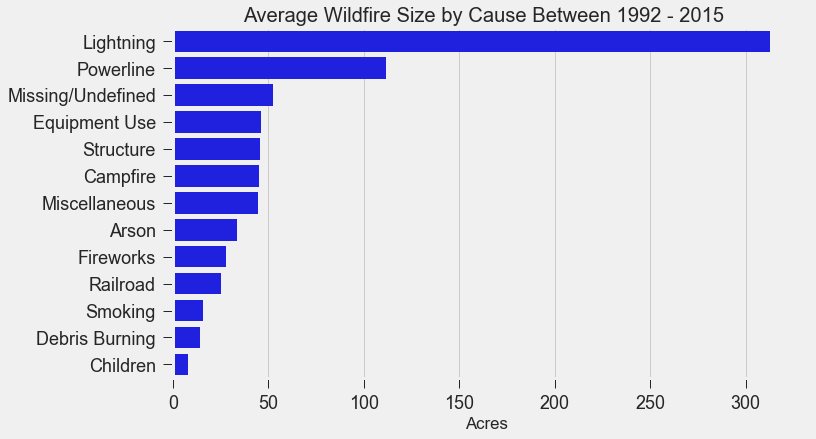 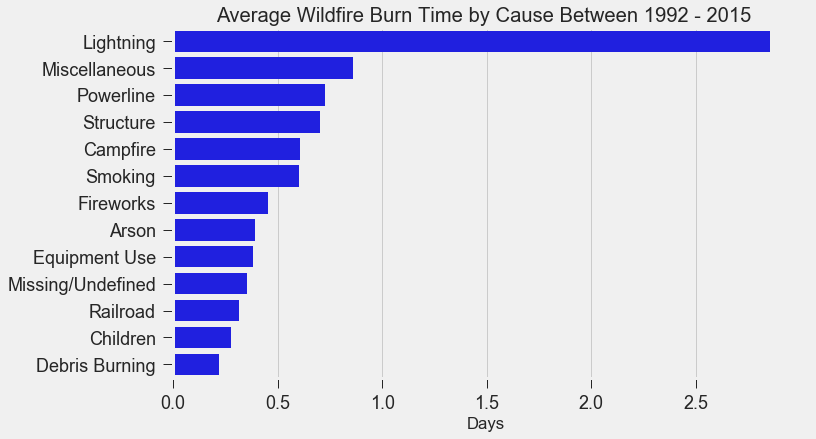 I wanted to explore whether the size of the fire and the number of days it took to contain the fire had any signal on the fire's cause. The above graphs indicates that fires caused by lightning and powerlines result in larger fires compared to fires caused by arson and debris burning, and that lightning-caused fires burns significantly longer other fires. These plots may indicate that wildfires caused by lightning have characteristics that make it easier to distinguish than others. Classification Metrics After trying different combinations of features on different models, the features that seem to have the most signal for the cause of wildfires, listed in order of importance, are as follows:
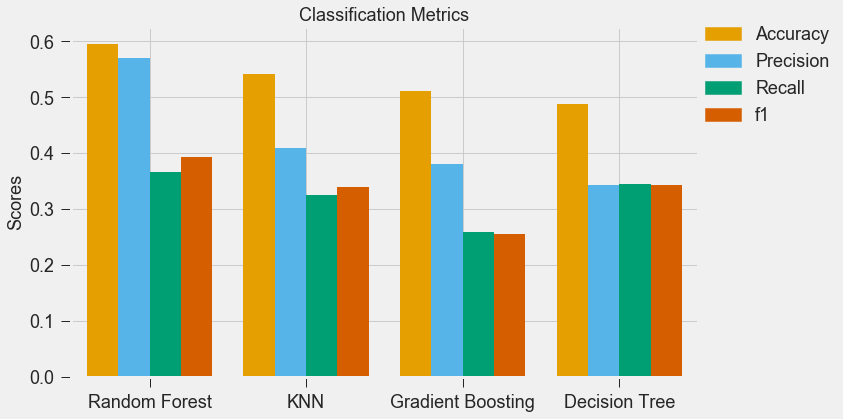 For my classification models, I chose to focus on K-Nearest-Neighbours and tree-based algorithms as these tend to work better with multi-class problems. By using sklearn's GridSearchCV, I tuned my hyper-parameters (k-neighbors, number of trees, tree depth, max features, min sample leafs, etc) and compared the classification metrics to determine the parameters that would yield the highest precision and recall, using macro averages. The graph above shows the results for different models with tuned parameters, where the random forest model seems to have obtained the best accuracy, precision and recall scores. 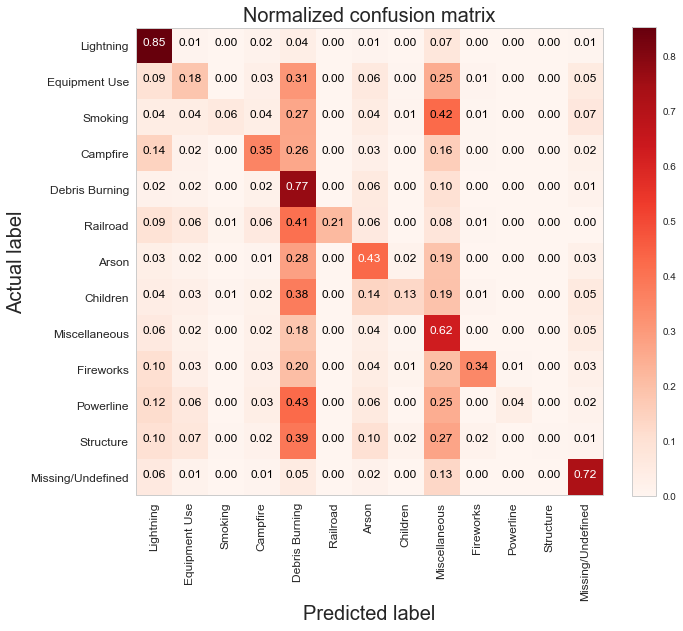 Confusion Matrix - Random Forest Model The above is the confusion matrix for my random forest model normalized to the actual class labels. From the confusion matrix, we can see that my model predicted a lot of false positives for debris burning and miscellaneous. What is interesting is that the accuracy for lightning class is quite high, with 85% of all events predicted correctly, and with much fewer false positives compared to debris burning and miscellaneous cases. This confirms my original hypothesis that lightning caused fires have characteristics that make it more distinguishable than other causes. If we take a look at the predicted versus actual label of the missing/undefined cases, we can also see that the accuracy is quite high, at 72%, with relatively low amount of false positives. This may suggest that wildfires with unknown causes may also share similar characteristics. Prediction of Missing/Undefined Wildfires To further explore these missing/undefined cases, I trained and fit another random forest model without the missing/undefined cases, then I used my trained model to predict on the missing/undefined cases. The graph below shows the predictions of over 70,000 missing/undefined causes of wildfires between 1992 and 2015, and shows that my model predicts almost 30,000 out of the 70,000+ cases of missing/undefined causes of wildfires are caused by arson, based on their location and fire characteristics. 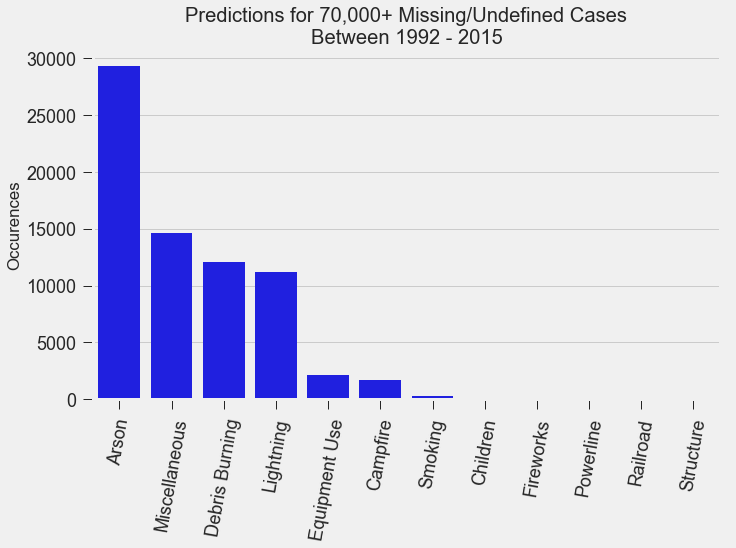 Prediction Application of Wildfire Causes Using this random forest model, I created an interactive Flask application to determine the highest probable cause of a wildfire for a given location, time of the year, days needed to contain the fire, and the size of the fire. I also created a d3 visualization of the total area of fires for a given US state as a proportion of the state's area. I will put links to those once I have it set up. The code for my analysis and visualizations can be found on my GitHub page. 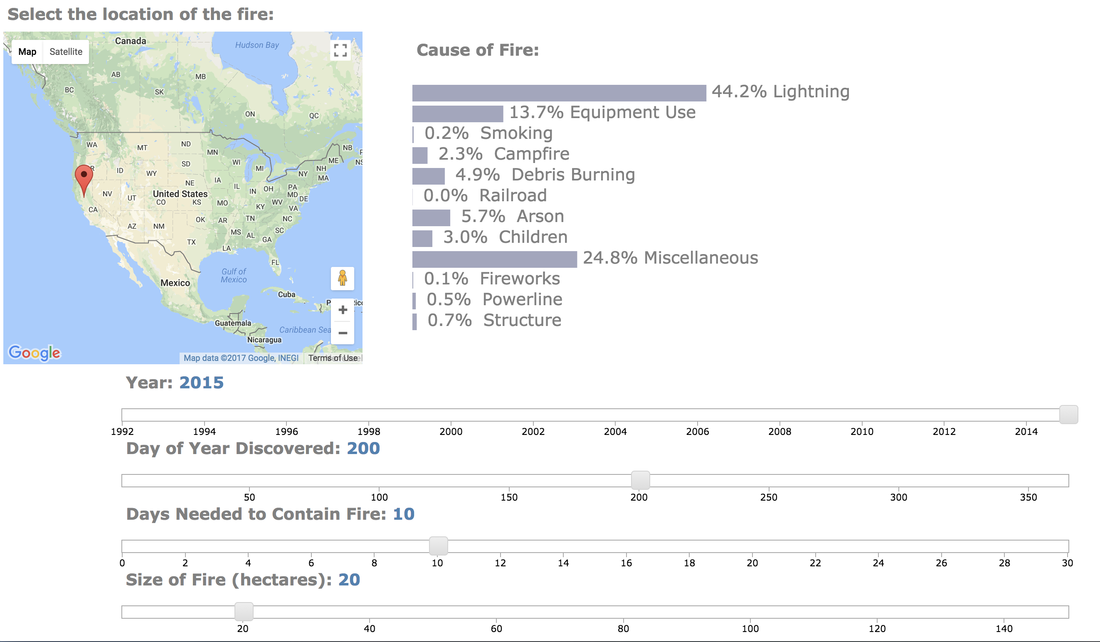 Flask Predictor Application 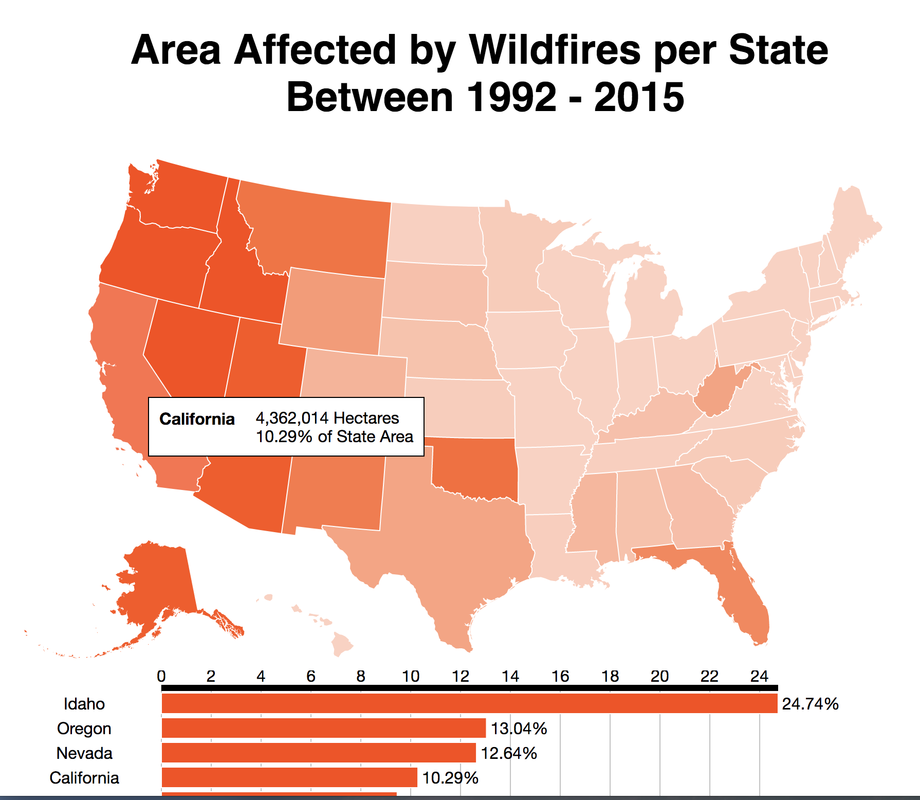 d3 Visualization Conclusions In this post, I've explored some defining characteristics of wildfires and discovered that wildfires caused by lightning may be more easily distinguishable due to its relatively larger size and burn time. I applied a trained random forest model to predict the 70,000+ missing/undefined cases of wildfires over the past 26 years, and the results show that a statistically significant majority of those fires were due to arson. My next blog post will be on my fourth project, codename Fletcher, where the main focus is to use unsupervised machine learning algorithms and natural language processing. The data I plan to use is comments from YouTube videos on the new iPhone X obtained using the YouTube API. By using Python's natural language toolkit (nltk) library, I will process the text data into vectorized data and use clustering algorithms to group the comments, and perform sentiment analysis to summarize each comment cluster to gain insights on how the public feels about certain features of the new iPhone.
0 Comments
Leave a Reply. |
Kenny LeungPassionate sports fan, wannabe golfer, avid gamer and world traveller. Archives
December 2017
Categories |
 RSS Feed
RSS Feed
