 Apple's New iPhone X Apple announced their new iteration of the iPhone in their keynote back in September, and the general public wasted no time voicing their opinions on social media (particularly on how the new Face ID "failed" during the keynote demo). For those of you who didn't catch the keynote, the new iPhone X comes with a bunch of new features, including a glass back to allow for Qi wireless charging, and Face ID which replaces Touch ID as the new way to unlock your phone and pay with Apple Pay. Consumer opinions on these new features were quite polarizing, with some praising Apple for the phone's sleek all-glass design, while some complaining about its apparent fragility. What if there was a way for Apple to determine the initial response prior the the phone's release? For my fourth project at Metis, I wanted to aggregate and analyze consumer sentiment based on YouTube comments using natural language processing and clustering methods to gain some insight on what people think about the features of the phone. Method For this blog post, I will focus on the process and the results from my analysis. The code for this project can be found on my GitHub page. In order to analyze sentiment on the different features of the iPhone, I needed to cluster the YouTube comments based on topics. The method I used to achieve this is as follows:
Scraping YouTube Comments To obtain my data, I scraped all the comments from the top 10 English-language YouTube videos based on view count using the YouTube API, stored the raw JSON in a Mongo database, and unpacked the JSON into a dataframe containing 60,000+ comments using Pandas.  Pandas DataFrame Text Pre-processing Now that I had my comments in a manageable dataframe, some of the text-preprocessing considerations I took were to remove stopwords, punctuations and stem the words using Natural Language Toolkit (NLTK) methods. Using sci-kit learn's TfidfVectorizer I further ignored uncommon terms by setting the minimum document frequency (min_df) parameter and created a weighted comment-term matrix shown below containing almost 2,500 columns of 1 to 3 word n-grams. To avoid the so-called "curse of dimensionality" when applying clustering methods to high-dimensional spaces, this sparse matrix needed to be reduced to a lower dimensional semantic space, allowing us to make valuable conceptual comparisons between comments without losing too much information after the dimension reduction takes place.  Sparse Comment-Term Matrix Latent Semantic Analysis & Clustering To reduce the comment-term space into a 300-dimensional semantic space, I used GENSIM, an open-source vector space modeling and topic modeling toolkit, which contains a module for Latent Semantic Analysis/Indexing (LSA/LSI) in Python. LSI performs a Singular Value Decomposition (SVD) on the comment-term matrix with TFIDF weightings to map all the terms in the corpus into a reduced term space and all the comments into a reduced comments space, and allows us to make arbitrary comment-to-comment comparisons using cosine similarity. Since every comment is the weighted sum of all of its terms, I can also use unsupervised learning to cluster my comment vectors into similar topics. The clustering algorithm I used was K-Means clustering, and to determine the number of appropriate clusters I analyzed the inertia scores and average silhouette coefficient scores. Inertia, or the within-cluster sum of squares criterion, can be recognized as a measure of how internally coherent clusters are and is a metric that we aim to minimize. A silhouette coefficient score, on-the-other-hand, relates to how defined your clusters are and is a metric we aim to maximize. Although the inertia plot below does not show a clear "elbow", I chose to use n = 17 clusters since there appears to be a local maximum average silhouette score. 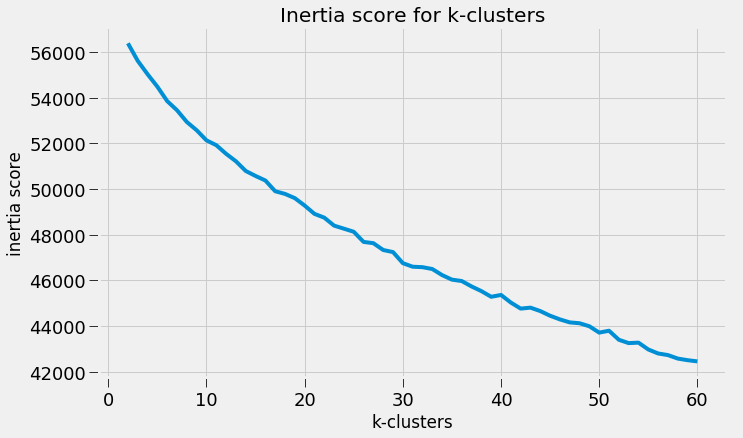 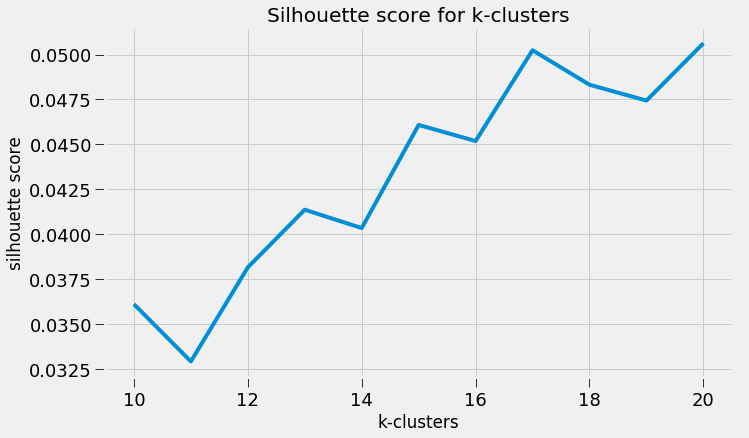 Sentiment Analysis After manually looking at comments in the different clusters, I determined the topic of each cluster and have shown some of those clusters in the picture below. In particular, I wanted to focus on analyzing the sentiment on the features of the new iPhone and decided to focus on three features: Face ID, Wireless Charging, and Aesthetics. I applied two different sentiment analysis tools (TextBlob and VADER) on the YouTube comments in these three topics to validate the results. 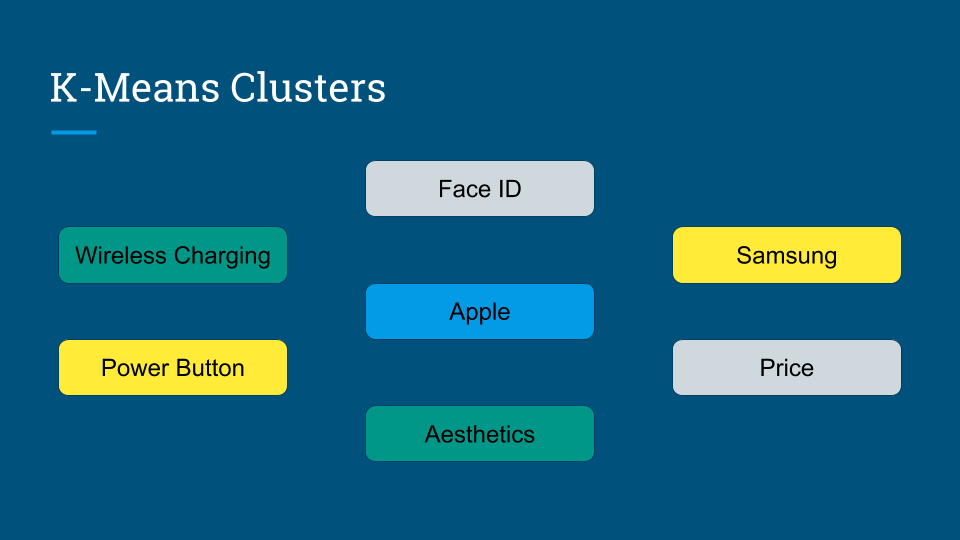 The below pie charts show the results of the sentiment analysis (the green slice represents positive comments, red represents negative, and blue represents neutral). For TextBlob, a comment is considered positive if the polarity score is positive, negative if the polarity score is negative, and neutral if the polarity score is equal to zero. The same method is applied to VADER for its compound scores. 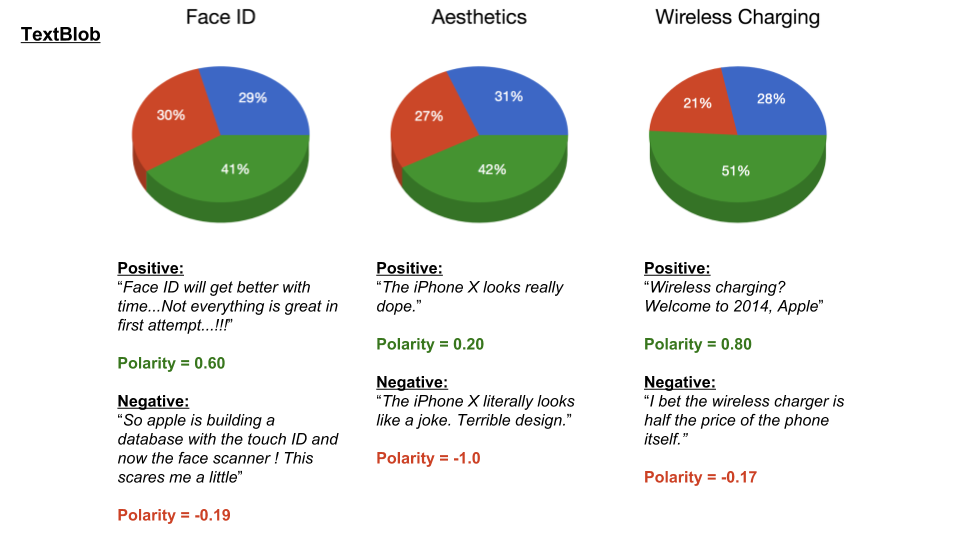 TextBlob Sentiment Analysis In the above picture, I have shown some of the comments and their corresponding TextBlob polarity scores. At first glance, the pie chart would suggest that the majority of comments related to the iPhone's wireless charging capabilities are positive, but if we look at the example positive comment ("Wireless charging? Welcome to 2014, Apple"), we can see that TextBlob does not detect sarcasm very well giving this particular comment a polarity score of 0.8. Below are the results from the VADER sentiment analysis and I have shown the same comments and their corresponding VADER compound score. Looking at VADER's results, it would appear that the comments related to the phone's aesthetics are mainly positive, but if we again look closely at the sample comments below, we can see that the clearly positive comment ("The iPhone X looks really dope.") was given a neutral compound score, while the clearly negative comment ("The iPhone X literally looks like a joke. Terrible design.") was given a positive compound score. 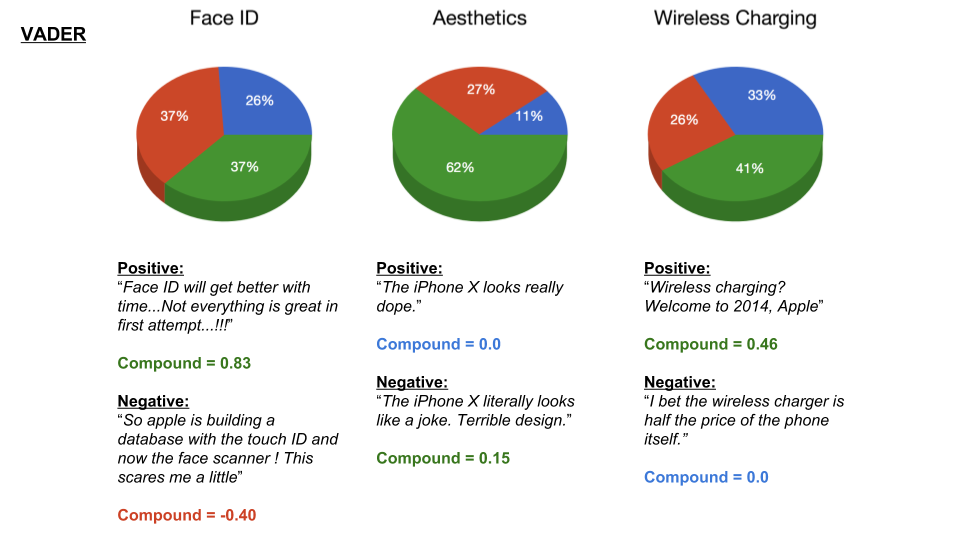 VADER Sentiment Analysis Conclusions In this post I’ve focused on my process of scraping YouTube comments, text-preprocessing and vectorization, clustering, and finally using two separate sentiment analysis tools to determine consumer sentiment on the features of the new iPhone X. The conclusion I can draw from the results is that although these sentiment analysis tools can give a broad snapshot of text sentiment, these methods are far from perfect. And even though there were a fair share of negative responses to the phone based on the YouTube comments, Apple can still rest assured that there will be people camped outside their stores at release to be the first to get their hands on their new products. Again, to view the code for this project, please refer to my GitHub page. My next blog post will be on my final project at Metis, where I use transfer learning to train a Convolutional Neural Network to classify a building's architectural style from images. Keep posted.
0 Comments
|
Kenny LeungPassionate sports fan, wannabe golfer, avid gamer and world traveller. Archives
December 2017
Categories |


 RSS Feed
RSS Feed
